西瓜书书本内容杂谈
把圈子变小,把语速放缓,把心放宽,把生活打理好
只能说快速过了一遍,花了一个多星期吧,然后后边的内容是一点也看不懂了(能发现前面记得比较详细,到了后边是看不懂一点了,脑壳痛QWQ
就不像是一本新手的入门书籍,太难受了ಥ_ಥ,了解概念这本书也不适合,还是转为看《邱锡鹏,神经网络与深度学习》和李沐动手学AI课的实践部分,ಠ_ಠ
第一章 绪论
1、预预测的值是离散值,这类学习任务叫做“分类”,如“好瓜”,“坏瓜”;若预预测的值是连续值,这类学习任务称为“回归”。
2、学得模型适用于新样本的能力,叫做“泛化”,泛化能力好,能更好的适用新样本。
3、西瓜问题的假设空间自顶向下、自底向上。
4、归纳偏好,对假设空间进行选择的启发式偏好,用一般性的原则来引导偏好,如”奥卡姆剃刀“法(Occam‘s razor)是一种常用的、自然科学研究中最基本的原则,即“若有多个假设与观察一致,则选择最简单的那个”,选择更为平滑的曲线。
5、不同算法针对不同问题有不同的拟合性,尽管看起来很差的算法(笨拙的算法)也有非常拟合的数据,。
6、所有算法的期望性能都差不多,E表示期望,下表ote表示训练集外误差(Out of Training set Error),Eote(La|X,f)表示的就是给定数据集和真实目标函数的情况下,算法La的训练集外误差的计算方式。(公式真的好难啊,脑壳痛QWQ)
7、NFL定理(No Free Lunch),针对具体的问题谈论算法的优劣,裁缝做衣服

8、历史发展过程,逻辑理论推理—>”知识期”(人为的去教电脑知识)—>自主学习知识,二十世纪八十年代是机器学习成为一个独立的学科领域、各种机器学习技术百花齐放。跳棋程序的发展历史:https://blog.creaders.net/u/5477/202405/487515.html
9、一些闪光的思想,“迁移学习”(Transfer Learning),“类比学习”(Learning By Analogy),“深度学习”(Deeping Learning)
10、课后习题看的头疼,完全看不懂,习题1.2直接可以用代码来解决了,厉害
11、机器学习的别称,萨缪尔(研制了一个西洋跳棋程序)将其定义为“不显示编程赋予计算机能力的研究领域”。
第二章 模型评估与选择
术语:误差(error),训练误差(training error)和经验误差(empirical error)是指学习器在训练集上得到的误差;泛化误差(generalization error);过拟合(overfitting)是当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都当成了具有的一般性质;相对的是欠拟合(underfitting)。
进行模型评估时,需要使用特定的方法来实现训练集S和测试集T的划分,并且训练集与测试集尽可能互斥。模型评估是通过实验测试来对学习器的泛化误差进行评估,在现实任务中往往还会考虑时间开销、存储开销、可解释性等方面的因素,这里暂且只考虑泛化误差。先交叉验证集选择模型,然后训练集训练模型,最后测试集评估模型
评估方法:评估方法不能理解,第二次看有了下面的一些理解。
训练集(Training Set):用于训练模型。验证集(Validation Set):用于调整和选择模型。
测试集(Test Set):用于评估最终的模型。
当我们拿到数据之后,一般来说,我们把数据分成这样的三份:训练集(60%),验证集(20%),测试集(20%)。用训练集训练出模型,然后用验证集验证模型,根据情况不断调整模型,选出其中最好的模型,记录最好的模型的各项选择,然后据此再用(训练集+验证集)数据训练出一个新模型,作为最终的模型,最后用测试集评估最终的模型。
- 留一法(Leave One Out Cross Validation,LOOCV):m个样本集合,拿出一个作为验证集,剩余m-1个作为训练集,这样进行m次当都的训练和验证,最后将m次验证结果取平均值,作为验证误差。缺点是计算量大,一般不作为实际使用
- K折交叉验证法(K-Fold Cross Validation):把数据集分成K份,每个子集互不相交且大小相同,依次从K份中选出1份作为验证集,其余K-1份作为训练集,这样进行K次单独的模型训练和验证,最后将K次验证结果取平均值,作为此模型的验证误差。当K=m时,就变为留一法。可见留一法是K折交叉验证的特例。根据经验,K一般取10。(在各种真实数据集上进行实验发现,10折交叉验证在偏差和方差之间取得了最佳的平衡。)
- 多次K折交叉验证(Repeated K-Fold Cross Validation):每次用不同的划分方式划分数据集,每次划分完后的其他步骤和K折交叉验证一样。例如:10 次 10 折交叉验证,即每次进行10次模型训练和验证,这样一共做10次,也就是总共做100次模型训练和验证,最后将结果平均。这样做的目的是让结果更精确一些。(研究发现,重复K折交叉验证可以提高模型评估的精确度,同时保持较小的偏差。)
性能度量:
错误率与精度
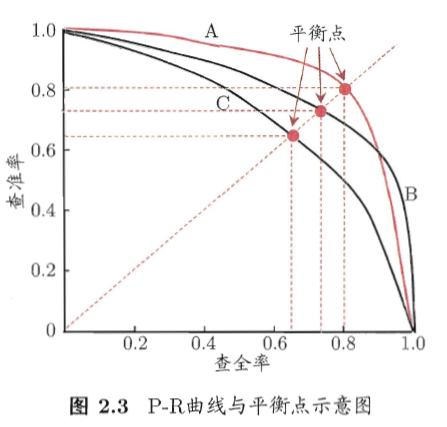
查准率P与查全率R:一组矛盾的度量,以P为纵轴,R为横轴,得到的曲线为P-R曲线图平衡点(Break Even Point)是查准率=查全率,查准率和查全率是一对“鱼”与“熊掌”,一把来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
例如,如果想将垃圾邮件都选取出来,可以将所有邮件都标签为垃圾邮件,那么查全率就接近于1,但这样查准率就会比较低;如果希望分类垃圾邮件的查准率足够高,那么可以让分类器尽可能挑选最有把握的垃圾邮件,但这样往往会有大量的垃圾邮件成为漏网之鱼,此时查全率就会比较低。
F1度量:F1是基于查准率与查全率的调和平均(harmonic mean)定义的,能够表达对于查准率和查全率 的不同偏好。

当β>0时,度量了查全率和查准率的相对重要性。β=1,退化为标准的F1
二分类问题得出的分类结果可以得出“混淆矩阵”。
ROC曲线和AUC(度量分类中的非均衡性),
ROC 关注两个指标:
TPR(True Positive Rate)表示在所有实际为正例(阳性)的样本中,被正确地判断为正例的比率,即:
TPR=TP/(TP + FN)FPR( False Positive Rate)表示在所有实际为反例(阴性)的样本中,被错误地判断为正例的比率,即:
FPR=FP/(FP + TN)\AUC值**(Area Unser the Curve)是ROC曲线下的面积

第三章 线性模型
- 线性回归(linear regression):试图完成一条直线f(x)=wx+b,并且使得f(x)接近y,如何衡量他们之间的差距,采用均方误差的方式(最常用的性能度量),在线性回归中,基于均方误差最小化来进行模型求解的方法叫做“最小二乘法”,最小二乘法就是试图找到一条直线,使所有样本到直线的欧式距离之和最小。对应的,多元线性回归(multivariate linear regression)就是对应于多个w和多个x,以向量形式来处理,
- 对数几率回归,使用Sigmoid激活函数
第四章 决策树
Decision Tree是一种解决分类问题的算法,监督学习主要有两种任务:分类(连续)、回归(离散)。
决策树算法采用树结构,层层推理来实现最终的分类。
决策树学习的三个步骤:特征选择、决策树生成、决策树剪枝(解决过拟合问题,随机森林很大程度减少过拟合)。
三种典型的决策树算法:ID3(采用信息增益)、C4.5(改进、采用信息增益比)、CART(采用基尼系数,CART树全称Classification And Regression Trees)
关于信息增益的理解:
熵:表示随机变量的不确定性
条件熵:在一个条件下、随机变量的不确定性能
信息增益:熵-条件熵,表示是在一个条件下,信息不确定性减少的程度。
详细解释:信息增益到底怎么理解呢?
剪枝处理,剪枝是决策树学习算法用于对付过拟合的主要手段,基本策略包括预剪枝、后剪枝。这里过拟合是指分支过多,训练结果“太好了”
第五章 神经网络
神经网络是一种模仿人脑神经系统的数学模型,称为人工神经网络,简称神经网络.在机器学习领域,神经网络是指由很多人工神经元构成的网络结构模型,这些人工神经元之间的连接强度是可学习的参数.
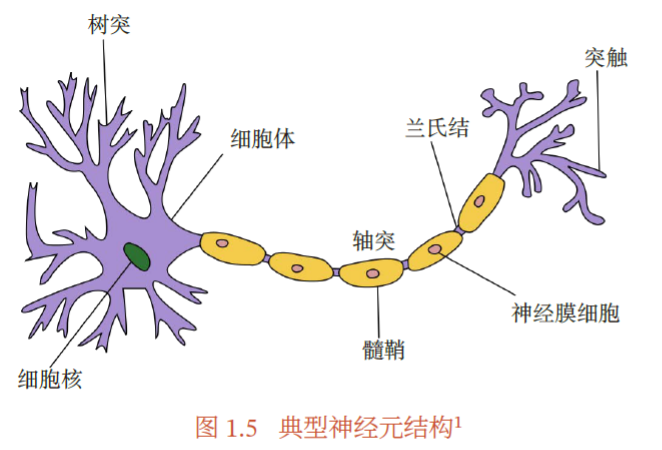
人脑神经元结构,典型的神经元结构可以分为细胞体和细胞突起:
(1) 细胞体(Soma)中的神经细胞膜上有各种受体和离子通道,胞膜的受体可与相应的化学物质神经递质结合,引起离子通透性及膜内外电位差发生改变,产生相应的生理活动:兴奋或抑制.
(2) 细胞突起是由细胞体延伸出来的细长部分,又可分为树突和轴突.
a ) 树突(Dendrite)可以接收刺激并将兴奋传入细胞体.每个神经元可以有一或多个树突.
b ) 轴突(Axon)可以把自身的兴奋状态从胞体传送到另一个神经元或其他组织.每个神经元只有一个轴突.
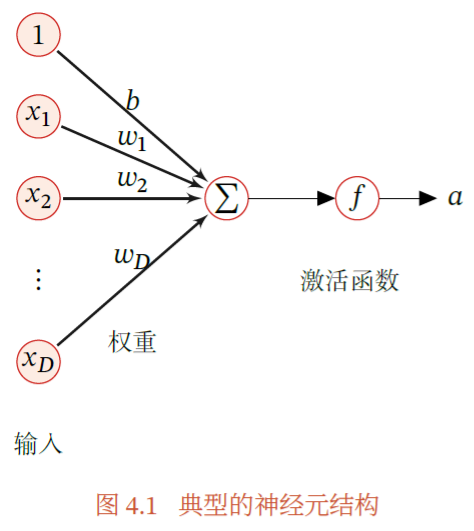
人工神经网络是为模拟人脑神经网络而设计的一种计算模型,它从结构、实现机理和功能上模拟人脑神经网络.人工神经网络与生物神经元类似,由多个节点(人工神经元)互相连接而成,可以用来对数据之间的复杂关系进行建模。
神经网络的不同节点的连接被赋予了不同的权重,每个权重代表了一个节点对另一个节点的影响大小,经过权重综合计算,将其输入到一个激活函数中得到一个新的活性值(兴奋或抑制)。
参考:邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.
第六章 支持向量机
支持向量机(Support Vector Machine,SVM)是一个经典的二分类算法,其找到的分割超平面具有更好的鲁棒性。
首先定义间隔γ表示整个数据集地所有样本到分割超平面地最小距离,γ越大,其分割超平面对两个数据集地划分就越稳定,不容易收到噪声地干扰。支持向量机的目标就是寻找一个超平面使得γ最大。
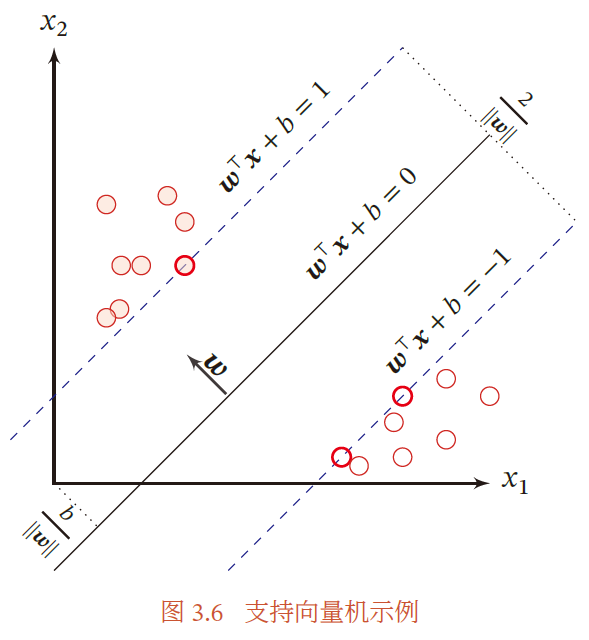
摘自 邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.
第七章 贝叶斯分类器
贝叶斯分类是一类分类算法的总称,贝叶斯算法是这类算法的核心,
极大似然估计(Maximum Likelihood Estimation,MLE)和贝叶斯估计(Bayesian Estimation)是统计推断中两种最常用的参数估计方法,这两种方法,也分别是频率派和贝叶斯派的观点
机器学习所要实现的是基于有限的训练样本尽可能准确的估计后验概率p(c|x),有两种方式来获取这个概率:
- 判别式模型,通过直接建模来获取后验概率
- 生成式模型,通过联合概率模型来建模,然后再获得后验概率,贝叶斯方法就是基于这个模型
贝叶斯理论模型的最优性,选择后验概率中最大的那一个作为预测结果
分类:朴素贝叶斯分类器、半朴素贝叶斯分类器(独依赖估计、TAN、AODE)、贝叶斯网。
通俗来讲,通过先验概率的计算后来获得后验概率的过程,其实就是通过已知的经验来判断后来的事情,经验越多,预测得到的东西也就越准。
这种分类方式有一定的缺点,根本原因是,在决策过程中假设太强了,而且可能面临维度灾难,要考虑的特征过多。
课后小故事,贝叶斯怎么有这么多谜团,这也能出名,他从事数学研究的目的是为了证明上帝的存在(笑。
第八章 集成学习
粗略看了一下
第九章 聚类
这是一种非监督学习的算法(与classification最大的区别),将不同性质的数据分成几个相同类型的数据,如何评定相同类型的数据,可以有下面这些标准:Euclidean distance, Cosine similarity, Manhattan distance, etc.
聚类算法的分类:
- Centroid-based Clustering (Partitioning methods)
- Density-based Clustering (Model-based methods)
- Connectivity-based Clustering (Hierarchical clustering)
- Distribution-based Clustering
Clustering in Machine Learning - GeeksforGeeks
第十章 降维与度量学习
第十一章 特征选择与稀疏学习
在机器学习中特征选择是一个重要的“数据预处理”(data preprocessing)过程,即试图从数据集的所有特征中挑选出与当前学习任务相关的特征子集,接着再利用数据子集来训练学习器;稀疏学习则是围绕着稀疏矩阵的优良性质,来完成相应的学习任务。
特征选择一般在获得数据之后首先需要进行的,因为在实际任务中经常会遇到维数灾难问题,其中提取的特征过多,大多数可能都是冗余的,所以要提取出重要特征来减少维数。
周志华《Machine Learning》学习笔记(13)—特征选择与稀疏学习—%E7%89%B9%E5%BE%81%E9%80%89%E6%8B%A9%E4%B8%8E%E7%A8%80%E7%96%8F%E5%AD%A6%E4%B9%A0.md)
第十二章 计算学习理论
顾名思义,Computational learning theory研究的是关于通过计算来进行学习的理论,分析学习人物的困难本质,为学习算法提供理论保证,并根据分析结果指导算法设计。
PAC(Probably Approximately Correct,可能近似正确) 学习可以分为两部分:
- 近似正确(Approximately Correct):泛化错误小于一个界限,一般为1/2,即,0 < 𝜖 <1/2;机器学习中一个很关键的问题是期望错误和经验错误之间的差异,称为泛化错误(Generalization Error).泛化错误可以衡量一个机器学习模型𝑓 是否可以很好地泛化到未知数据.
- 可能(Probably):一个学习算法可能以一定的概率学习到这样一个近似正确的假设。
第十三章 半监督学习
在许多ML的实际应用中,很容易找到海量的无类标签的样例,但需要使用特殊设备或经过昂贵且用时非常长的实验过程进行人工标记才能得到有类标签的样本,由此产生了极少量的有类标签的样本和过剩的无类标签的样例。因此,人们尝试将大量的无类标签的样例加入到有限的有类标签的样本中一起训练来进行学习,期望能对学习性能起到改进的作用,由此产生了半监督学习(Semi-supervised Learning)。
在做半监督学习(Semi-supervised Learning)的时候通常的情景如下:
- unlabeled data的数量要远大于label data
- 直推半监督学习(Semi-supervised Learning)只处理样本空间内给定的训练数据,利用训练数据中有类标签的样本和无类标签的样例进行训练,预测训练数据中无类标签的样例的类标签
- 归纳半监督学习(Semi-supervised Learning)处理整个样本空间中所有给定和未知的样例,同时利用训练数据中有类标签的样本和无类标签的样例,以及未知的测试样例一起进行训练,不仅预测训练数据中无类标签的样例的类标签,更主要的是预测未知的测试样例的类标签。
半监督学习的需求非常强烈,因为在现实应用中往往能够很容易的收集到大量没有标记的样本。
第十四章 概率图模型
概率图模型(probabilistic graphical model, PGM),是一种学习任务的框架描述,它将学习任务归结为计算变量的概率分布,巧妙的结合了图论和概率论。
按照概率图中变量关系的不同,概率图模型可以大致分为两类:
- 贝叶斯网络:有向图模型,使用有向无环图表达关系(通常,变量间存在显式的因果关系)
- 马尔科夫网络:无向图模型,使用无图表达关系(通常,变量间存有关系,但是难以显式表达)
第十五章 规则学习
机器学习中的“规则”(rule)通常是指语义明确、能描述数据分布所隐含的客观规律或领域概念
目标是产生一个能覆盖尽可能多的样例的规则集。
规则集生成的过程是一个贪心搜索的过程,因此为缓解过拟合的风险,最常见的做法就是剪枝(pruning)。
第十六章 强化学习
与监督学习不同的是,强化学习不需要带标签的输入输出对,同时也无需对非最优解的精确地纠正。其关注点在于寻找探索(对未知领域的)和利用(对已有知识的)的平衡。在一个学习过程结束后,根据获得的“奖励”来学习,并且进一步预测下面的东西。



